Computer databases have a significant impact in computing today and form the backbone of electronic commerce transactions. For example, keeping employee and customer records, tracking inventories, and monitoring and reporting sales are among the most important and most computerized activities in many business organizations. Governments, the banking, healthcare, insurance, travel, retail sales, and other industries, could not function today without computerized record keeping. Neither could social media applications. All of these activities depend upon database management systems for storing and retrieving data. In this lesson you will learn about today's most popular database model -- the relational database model. In addition, you will begin your exploration of the most widely-used database retrieval/update language -- SQL (Structured Query Language).
Long before word processing became common, businesses were using databases to store and review much of their important information. As the name suggests, a database is a (often large) collection of data about some enterprise or subject. But the term database means more than just a large data store or data bank. What distinguishes a database is the fact that it is organized in a way that makes possible effective and efficient retrieval of information stored in it. We use the term database management system (DBMS) to refer not only to the data itself but also to the methods and techniques used to store and retrieve that data.
The demands for information management increased dramatically during the late 1960s and early 1970s. These changes affected not only the scale and complexity of database management systems, but also the manner in which these systems conducted business. The kinds of computing applications and problems gaining attention were quite a bit more difficult than the payroll and inventory systems that had comprised the bread and butter of earlier programming applications. As interactive or transactional computing became more commonplace, it became desirable to be able to query the database systems for particular information when it was needed. A convenient query language or method for constructing database queries was required to achieve this.
Of course, these new applications also demanded even more sophisticated data management tools. A major advancement was the creation of data management systems that allowed access to more than one related file-the first true database management systems. These systems gave the programmer tools and methods for creating and accessing a group of related files. Special fields, called link fields, were used to relate records stored in two different files. These link fields contained disk addresses to give quick access to related information stored in another file.
The linked structures these systems employ have come to be called the network database model because the files are connected by a network of physical links. Updated versions of many network database systems are still in use today. In the network model, the programmer is dealing with a physical model of the database. For example, to implement a database retrieval, the programmer must manipulate the indices and links built into the database itself in order to access the required data. These systems are optimized for speed and efficiency, but they are relatively complex to use.
The relational database model was introduced in the late 1970s as an alternative database model. The relational model presents the user a more conceptual view of the database rather than the physical organization employed by the network model. The relational model does not employ link fields to relate records in different files. Rather, in this model, related information is located when it is needed from the logical relationships among items in the files.
For example, if we store data about employees in one file and the week's work record in another, we obviously need access to both when processing the week's payroll. In the network model, the necessary links between the two files would be defined when the record data fields were created. To process the payroll, the programmer would manipulate the links present in the design of the database.
In a relational model of the same data, there are no physical link fields present, only the logical relationship between the two files guide the combination of their data. Because the file relationships are logical, the user is relieved of the details of how the files are physically organized. Consequently, this reduces the level of detail required to employ a relational database model successfully. Indeed, the relational model is much more intuitive and accessible to the nonprogrammer.
Both the network database model and the relational database model are in widespread use today, and both will no doubt continue to be important for years to come. This is because each model has its own distinctive merits. The network model's strength is its efficiency, while the relational model offers much more flexibility. The vast majority of today's electronic commerce applications are based on the relational model and so we will focus exclusively on this model in our work.
In relational databases, the data to be collected and stored is divided into separate tables, which are stored as separate files. Relational database design involves deciding what tables to use and how the data will be distributed among these tables. We must also be certain we have built into the design the natural logical relationships among the data, for it will be these relationships that we use to retrieve related data from different tables. This may all sound a bit strange just now, but an example will help make it more meaningful.
Suppose we wish to keep track of sales orders for our enterprise. Wouldn't it seem natural and desirable to also keep records on our customers and the products we sell, as well as the orders per se? In fact, we have just identified three important entities in our data storage requirements; customers, products, and sales orders. This is always the first step in designing a database: identify the important entities about which we wish to keep and retrieve data.
Of course, we also want to keep in mind how the entities are related. In this case, customers place orders for products. So the relationships are clear. Each customer will place many (we hope) orders. Likewise, we hope each of our products are the focus of many orders. All this suggests that we need three tables: one to hold customer information, one to hold product information, and one to hold order information.
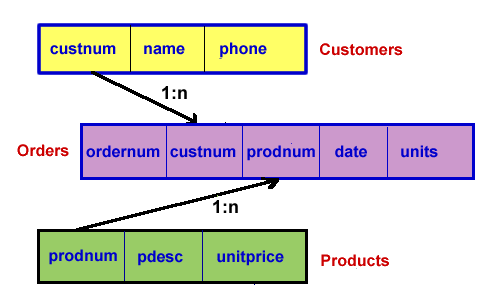
The order information will be related to both the customer information (who placed the order?) and the product information (what product was ordered?). Here's a diagram showing how we might organize this information into three related tables. Note that for the purpose of our example, we will keep the particular information about each of these entities quite restricted to make our examples easier to display. In a real commercial application of this type, we'd no doubt store lots more information about our products and our customers.
The attribute names (custnum, name, and so on) are often referred to as simply column names. The rows in the table represent information about one particular entity. These rows are called records. For example each row (or record) in the Customers table represents information about one particular customer. Likewise, a record in the Orders table represents information about a particular order that was placed, and so on. We represent the relationships between the table as a ratio. The 1:n (read one-to-many) notation means that one record in the first table can correspond to many records in the second table. So for example, a single customer can place many orders, and a single product can be ordered many times.
Let's consider how we could use the relational database design shown in the above figure to retrieve some information. Suppose we wish to list the product numbers for all the items bought by customer John Jones. We could do this by first looking up the record for John Jones in the Customers table. We would then use John Jones' customer number (custnum) to search the Orders table and list the product number for the products John purchased. The information we needed required us to access two tables: Customers and Orders. The logical link between the two tables is the fact that both contain the custnum column.
Suppose now that we wish to list the product descriptions for all the items bought by customer John Jones. We could do this by first looking up the record for John Jones in the Customers table. We would then use John Jones' customer number to search the Orders table and record the product number for the products John purchased. Then using the product number we can get the product descriptions from the Products table. The information we needed this time required us to access all three tables. The logical links between the two tables are provided by their common columns: custnum for Customer and Order and prodnum for Products and Orders.
When designing a relational database structure, we should make sure we have provided all relevant and appropriate logical relationships within the record structures for each table. If we do this, then even queries that might not have been anticipated when the database was designed are possible. We call these unanticipated queries ad hoc queries, because they are constructed as needed. The relational database model provides the flexibility to construct these easily.
The ability to perform database queries is the most valuable feature of any database management system. Queries are requests for specific information satisfying some stated criteria. Queries are written in a query language which, like a programming language, has a specific syntax. In fact, much of a database management system's value for its users will be based on the convenience and power of its query language. Use of these languages requires no programming in the traditional sense. Query languages are self-contained, so that once a user masters the language, he or she can pose any potential queries to the system.
Given the importance of query languages, it will come as no surprise to you that database management system designers and researchers have expended a great deal of effort to make these languages both user friendly and as powerful as possible. There are several popular models on which most are based. One of these models is called QBE (for Query-by-Example). QBE is not standardized and there are actually many different versions of QBE being used. All these versions are based on a graphical interface paradigm that allows a user to construct a generalized example of the data he or she would like to retrieve.
There has been some attempt to standardize a query language for all relational database systems. The leading candidate for standardization is SQL (for Structured Query Language). Although no such standard has been adopted officially, SQL (usually pronounced "sequel") is widely used and is becoming a de facto standard. Most relational database systems offer a query language containing at least a subset of SQL. This is very good news for database users because it means that an adequate knowledge of SQL will allow them to move freely from one database system to another.
SQL queries are formed with an English-like syntax, often employing a SELECT <columns> FROM <table> WHERE <criteria> format. We adopt the convention of displaying the SQL reserved words in all caps. Table and column names are case sensitive and must be used exactly as they are defined as far as case goes. We'l investigate SQL in some detail in the next lesson, but here's a quick example of the SQL statement to select all the records from the Customers table using SQL:
SELECT * FROM Customers
The * is a wildcard character which means in this case that all the columns are to be selected from table Customers.
In this activity, you will be asked to use the world's most popular open source database product MySQL to experiment with the example database we defined above. We should point out that the purpose of this and succeeding activities will be to illustrate the database concepts and SQL techniques we're discussing.-- not to teach you about the MySQL database management system. You will need some familiarity with MySQL to actually implement the activities as described.
Customers |
||
| custnum | name | phone |
| 100 | Jones, Bill | 864-555-1211 |
| 101 | Smith, Ed | 803-555-1346 |
| 102 | Morgan, Sue | 803-555-1111 |
| 103 | Diaz, Jorge | 864-555-3333 |
| 104 | Wendt, Bill | 704-555-1111 |
| 200 | Parks, Fred | 704-555-2222 |
| 201 | Smith, Mary | 803-555-5533 |
| 202 | Lopez, Rick | 704-555-1919 |
| 203 | Smith, Karen | 803-555-2323 |
| 204 | Jones, Brandy | 828-555-4444 |
| 300 | Martinez, Lucy | 828-555-8899 |
| 301 | Lopez, David | 828-555-3333 |
| 302 | Jones, Mark | 803-555-4411 |
Products |
||
| prodnum | pdesc | untiprice |
| 23451 | Ace red bike | 89.59 |
| 23460 | Ace blue bike | 95.45 |
| 23780 | Inline skates | 87.00 |
| 32223 | Standard bike | 58.00 |
| 45222 | Trainer wheels | 14.87 |
| 45232 | Bike basket | 12.23 |
| 45360 | Bike helmet | 34.00 |
Orders |
||||
| ordernum | prodnum | custnum | date | units |
| 1 | 23451 | 200 | 4/5/2003 | 3 |
| 2 | 45360 | 204 | 6/5/2003 | 12 |
| 3 | 45360 | 300 | 5/3/2003 | 4 |
| 4 | 23460 | 302 | 4/2/2003 | 5 |
| 5 | 23460 | 301 | 7/11/2003 | 4 |
| 6 | 45232 | 101 | 6/23/2003 | 8 |
| 7 | 45222 | 201 | 3/23/2003 | 3 |
| 8 | 45222 | 204 | 6/12/2003 | 8 |
| 9 | 32223 | 204 | 6/12/2003 | 10 |
| 10 | 23780 | 201 | 6/1/2003 | 7 |
| 11 | 23460 | 102 | 7/1/2003 | 14 |
| 12 | 23460 | 302 | 6/30/2003 | 3 |
| 13 | 32223 | 203 | 5/2/2003 | 5 |
| 14 | 32223 | 104 | 5/14/2003 | 8 |
| 15 | 45232 | 103 | 5/1/2003 | 12 |
| 16 | 45232 | 204 | 4/14/2003 | 6 |
| 17 | 23451 | 100 | 5/23/2003 | 11 |
| 18 | 45360 | 302 | 5/11/2003 | 10 |
| 19 | 23780 | 301 | 4/16/2003 | 11 |
| 20 | 45222 | 101 | 4/26/2003 | 8 |
| 21 | 23460 | 102 | 5/7/2003 | 11 |
| 22 | 45232 | 300 | 6/3/2003 | 18 |
| 23 | 45232 | 204 | 6/15/2003 | 2 |
| 24 | 23780 | 203 | 5/3/2003 | 1 |
| 25 | 45360 | 104 | 4/19/2003 | 7 |
| 26 | 23460 | 200 | 4/3/2003 | 11 |
| 27 | 23451 | 203 | 7/3/2003 | 4 |
| 28 | 32223 | 201 | 7/5/2003 | 5 |
| 29 | 32223 | 202 | 6/25/2003 | 7 |
| 30 | 45232 | 201 | 5/30/2003 | 2 |